MobileNet 学习笔记
学长推荐 (5/20)
堂堂复工!
Motivation
MobileNet 是 Google 提出的,目标是在移动设备上实现一个小型神经网络。
V1
MobileNet-V1 提出的最重要的创新点就是深度可分离卷积,V1 的所有东西只有一句话:把 VGG 中的卷积替换为深度可分离卷积。
具体来说,我们考虑 $H\times W\times C_{in} \rightarrow H’\times W’\times C_{out}$ 的一个卷积。标准卷积是用$C_{out}$ 个 $K\times K \times C_{in}$ 的卷积核,对每个通道进行卷积之后加权求和。那么一次卷积的开销是: $H’ \times W’ \times C_{out}\times C_{in}\times K\times K$,当 $C$ 很大的时候就爆炸了。
深度可分离卷积的想法是:最开始我们会把所有 $C_{in}$ 个通道的东西全部分开,对于每一个 $H\times W \times 1 $ 的分离后的层数,我们用 $K\times K\times 1$ 的卷积核进行操作。这样做了之后时间复杂度变成 $C_{in}\times H’\times W’\times K\times K$。
接下来考虑每个通道的加权,也就是进行逐点卷积。我们用 $C_{out}$ 个尺寸为 $1\times 1\times C_{in}$ 的卷积核进行卷积,然后这样卷完就达成了加权平均的想法,同时也调整了通道。 时间复杂度变成 $\text{C}{\text{Pointwise}} = 1 \times 1 \times C{in} \times C_{out} \times H’ \times W’ $
这样拆分过后,时间复杂度就变成了原本的 $\frac{1}{C_{out}}+\frac{1}{K^2}$ 。我们实际上一般取 $K = 3$,那么效率就到了原本的九分之一,$C_{out}$ 越大越有优势。而这个拆分的想法其实本质上是把一次卷积的操作给解耦成深度和空间上的。
代码参考:
1 | self.conv = nn.Sequential( |
在 dw(depthwise) 部分,当 groups = hidden_dim 的时候,他会自动执行深度卷积,也就是把输入通道分成 hidden_dim 份,每份单独用一个卷积核进行卷积。
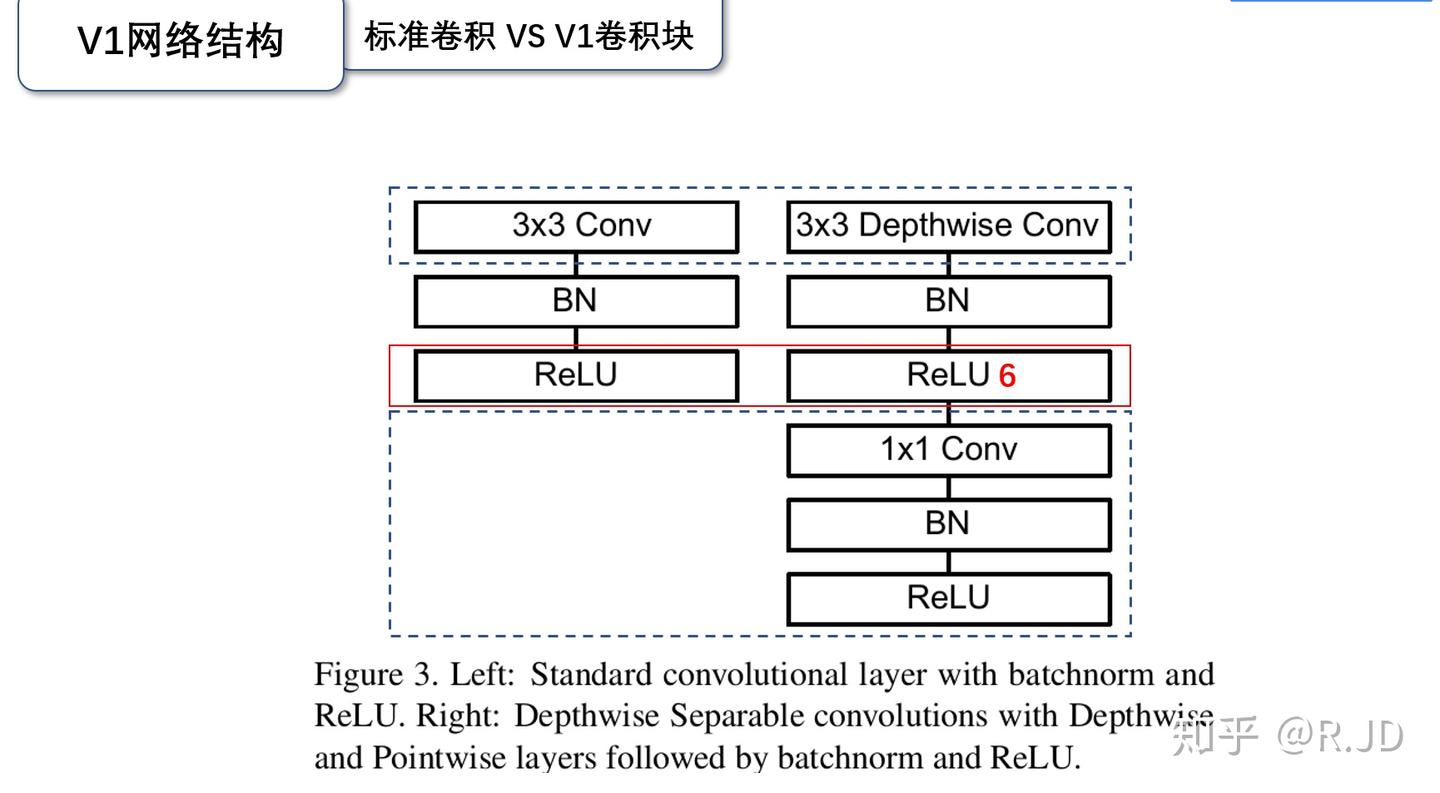
这是两种卷积的对比图,这里要注意,MobileNet 把 ReLU 换成了 ReLU6,这是因为 ReLU6 对于大于 6 的值全部变为了 6,在低精度运算下有更好的表现。看实验结果: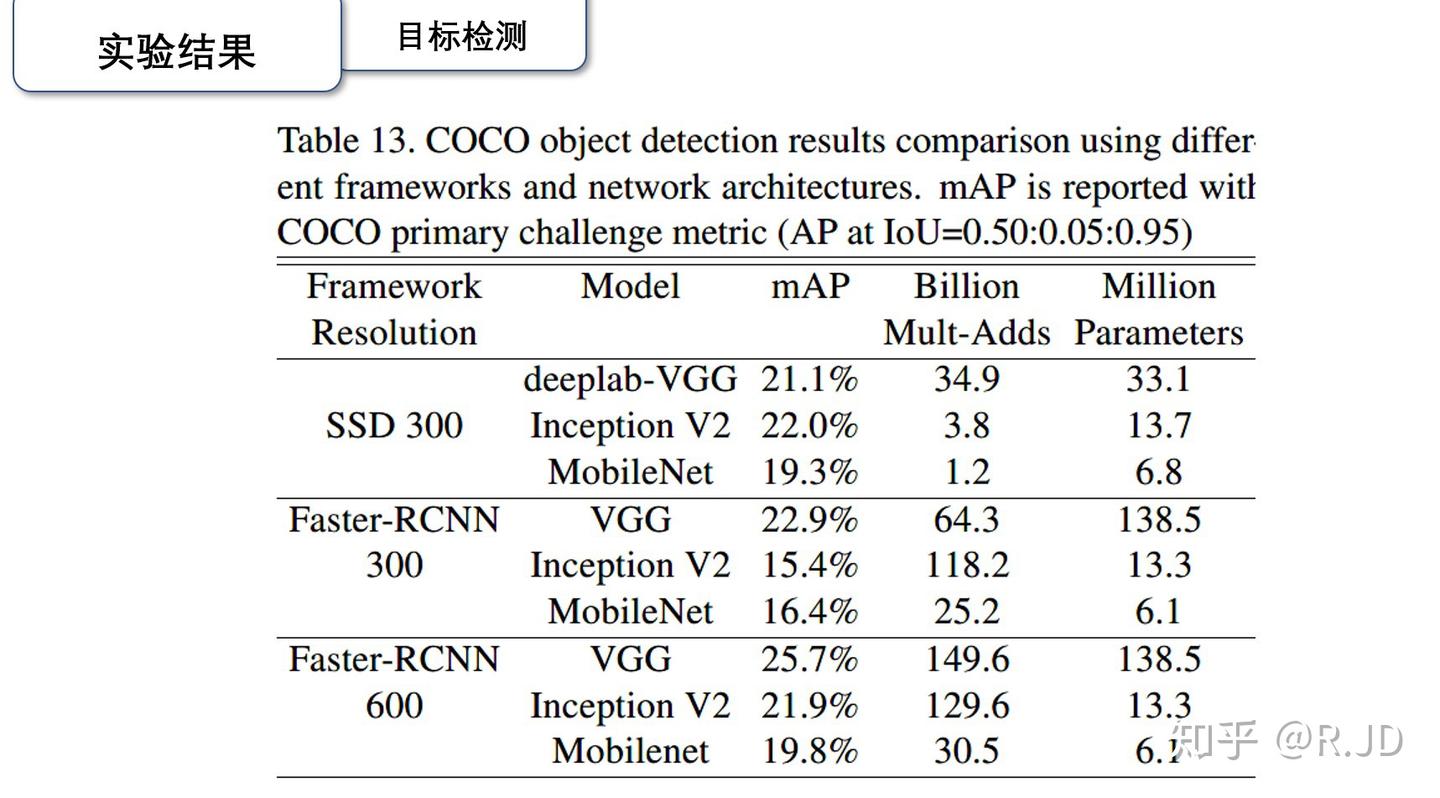
V2
有人在实际使用 V1 的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的。如何解决?
Linear bottleneck
作者发现,问题出在 ReLU 上,当维度比较低的时候,ReLU 实际上会丢掉很多东西,下图展示了不同维度的流形:

为了解决这个问题,作者把最后一个激活层换成了线性的,也就是论文名中的 Linear bottleneck.注意这里我们只在最后一层用 Linear 是因为,如果我们在最开始就用 Linear 而非 ReLU,那么会削弱模型的非线性刻画能力。
Expansion layer
深度卷积本身没有改变通道的能力,所以我们如果来的通道很少的话,深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在深度卷积之前使用逐点卷积进行升维(升维倍数为t,t一般=6),再在一个更高维的空间中进行卷积操作来提取特征:
也就是如下:
1 | hidden_dim = round(inp * expand_ratio) |
Inverted residuals
我们刚才讲到,MobileNet v1 本质上是修改了卷积的一个 VGG。借鉴 ResNet 的经验,我们引入 shortcut 机制,也就是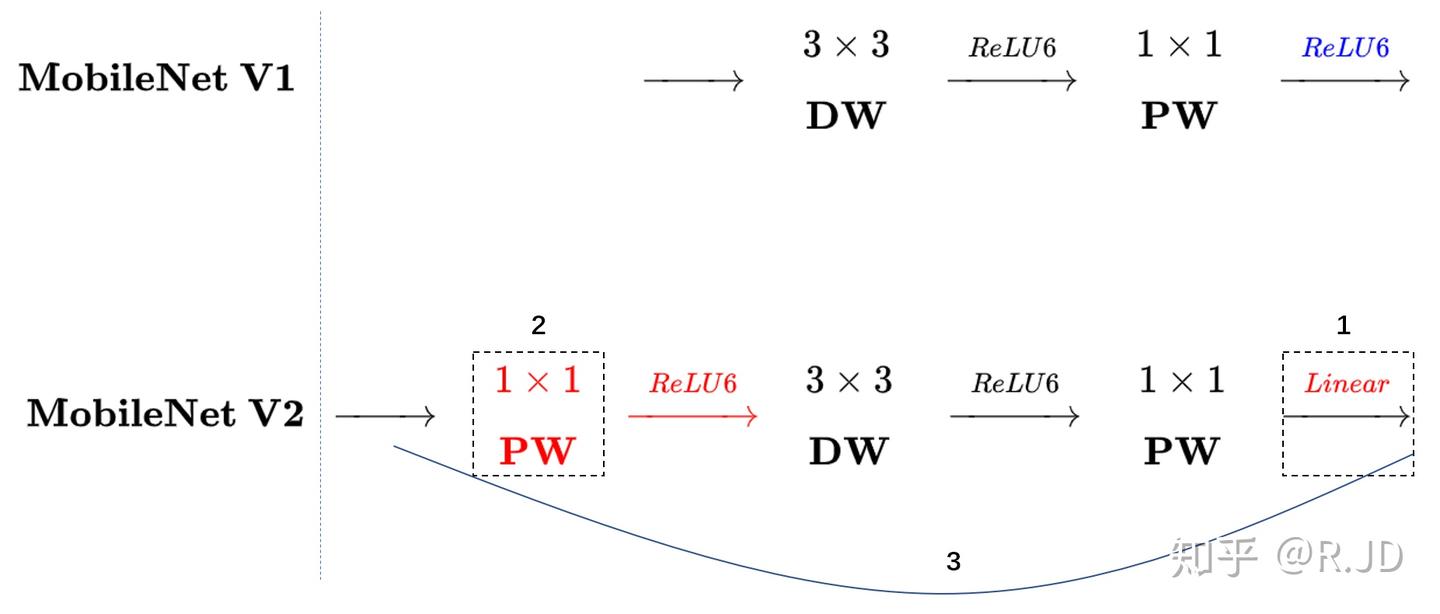
他和 Resnet 的区别在于,ResNet 中间使用了标准的卷积块。
下面看一下标准的网格设计:
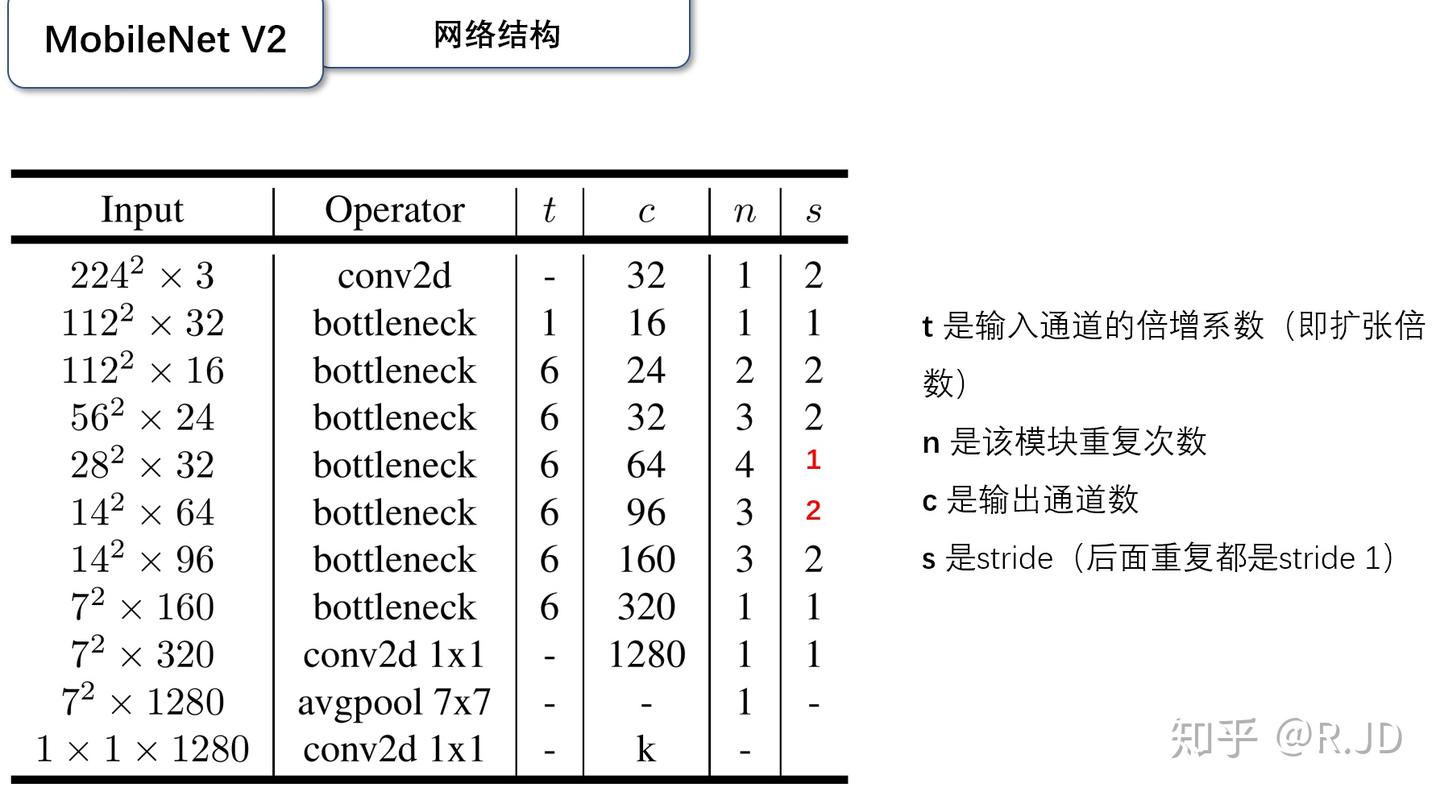
V3
H-swish
swish 是 Google 2017 年提出的激活函数,在深层网络的效果比 ReLU 好多了。同样也是因为性能因素,使用一个 ReLU6 来近似: 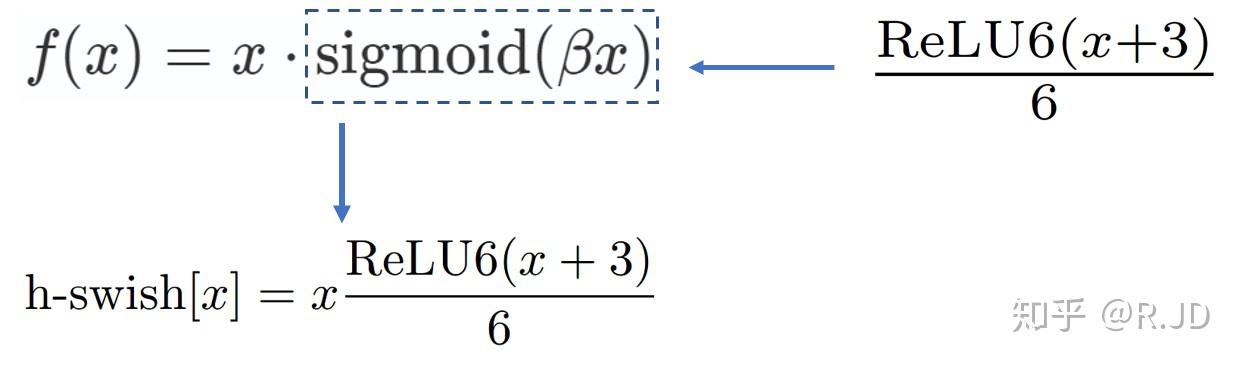
SE attention
SE 模块是一种通道注意力机制。它能自动学习每个特征通道的重要性,然后根据这个重要性去增强有用的特征通道、抑制无用的特征通道。简单来说,它让网络把计算资源更多地分配给包含关键信息的通道。
如何工作的?
- Squeeze (压缩): 首先,通过全局平均池化(Global Average Pooling)将每个通道的空间信息($H \times W$)压缩成一个单一的数值。这个数值可以理解为该通道的全局响应或“概要”。
- Excitation (激励): 接着,这个概要信息会经过两个全连接层(一个降维,一个升维)和非线性激活函数(取h_Sigmoid),最终为每个通道生成一个 0 到 1 之间的权重(或称为注意力分数)。
- Scale (缩放): 最后,将这些权重逐通道地乘回到原始的特征图上,就完成了对不同通道的重新加权。
其他优化:
修改第一个卷积层 (Stem)
MobileNetV2 的第一层是一个 3x3 的标准卷积,将 3 通道扩展到 32 通道,计算量不小。MobileNetV3 将其改为一个同样是 3x3 但更小的卷积层(16通道),并使用了 h-swish 激活函数,将初始的计算成本降了下来。
重新设计最后阶段 (Last Stage)
MobileNetV2 的最后几层为了生成丰富的特征,通道数很高,计算量密集。V3 对这部分进行了大刀阔斧的改造:
- 它移除了 V2 中最后一个 block 里的 1x1 扩展卷积层,并直接在深度卷积的输出上进行特征池化。
- 将这个池化层提前,并在池化之后再接一个 1x1 的卷积层进行特征融合和升维。
MobileNet 学习笔记